GRPO Post-Training for Math Reasoning on Qwen3-0.6B
From SFT to GRPO: a systematic exploration of post-training strategies that improved math reasoning accuracy from 38.2% to 55.2% on Qwen3-0.6B-Base, with reward function design and None discrimination.
TL;DR
This post documents a 14-experiment journey of post-training Qwen3-0.6B-Base for mathematical reasoning. Starting from SFT (supervised fine-tuning), I discovered that SFT alone cannot substantially improve a small model's reasoning ability. Switching to GRPO (Group Relative Policy Optimization) — the algorithm behind DeepSeek-R1 — unlocked significant gains: accuracy improved from 38.2% to 55.2% (+17pp). The key challenges were reward function design and teaching the model to recognize unsolvable problems.
Phase 1: SFT Experiments — The Bottleneck
Cold-start SFT
I began with a cold-start dataset of 8,323 math problems (with <think> reasoning chains) and performed full-parameter SFT on Qwen3-0.6B-Base (4 epochs, lr = $2 \times 10^-5$, DeepSpeed + OpenRLHF).
Result: 39.5% accuracy (valid_1000), barely above the 38.2% baseline.
Scaling SFT Data — Regression
I expanded the training set by merging in three additional high-quality datasets from teammates. Counterintuitively, accuracy dropped to 36.7%. The new data shifted the distribution in ways that hurt overall performance.
Key insight: For a small model like Qwen3-0.6B, SFT alone cannot produce meaningful capability gains. However, Base model's pass@5 reached 62.6% — the model has the knowledge, but greedy decoding cannot reliably access it. This gap between greedy and pass@k is exactly what RL can close.
Phase 2: GRPO Validation — RL >> SFT
Why GRPO?
GRPO samples $K$ completions per prompt and computes group-relative advantages, directly optimizing the generation distribution. It narrows the greedy-pass@k gap without needing additional labeled data — the reward signal comes from comparing generated answers to ground truth.
Setup
- Framework: verl 0.7.1
- $K=10$, Temperature $=0.7$, LR $=1 \times 10^-6$
- Single RTX 5090 32GB (Actor + vLLM rollout dual-engine)
- 1,772 GRPO training prompts filtered for extractable answers ($\boxed$)
Results
| Model | Training | Accuracy |
|---|---|---|
| Base (Qwen3-0.6B) | None | 36.2% |
| SFT Coldstart (best) | Full SFT | 39.5% |
| GRPO from Base | GRPO 5ep | 46.6% |
GRPO from Base directly achieved 46.6% — +7.1pp over the best SFT. This was the first clear validation that RL is the right path.
Phase 3: Teaching "I Don't Know" — None Discrimination
The Problem
13% of the validation set consists of critical thinking problems that are intentionally underspecified — the correct answer is None. After initial GRPO training, the model scored 0% on these problems: it always hallucinated an answer instead of recognizing impossibility.
Two-Stage Solution
- SFT Stage: Fine-tune the GRPO checkpoint on 150 None-labeled examples (with full "condition check → missing info → None" reasoning chains) + 400 cold-start examples (lr = $2 \times 10^-6$, 2 epochs).
- GRPO Stage: Resume GRPO training with the reward function giving bonus points for correct None answers.
Results
| Model | Overall | None Acc | False Positive | Weird Tokens |
|---|---|---|---|---|
| GRPO Base→ep5 (no None) | 46.6% | 0% | 3.8% | — |
| SFT None only | 40.7% | 67.7% | 22.1% | 10.8% |
| GRPO Mixed (SFT→GRPO) | 55.7% | 80.0% | 14.0% | 14.0% |
Critical insight: Build math ability first (GRPO), then teach None discrimination (SFT), then consolidate both (GRPO). Doing None SFT directly from Base caused false positives to explode above 45%.
Phase 4: Reward Function Design — Three Generations
The reward function is the most critical component of GRPO. I iterated through three versions:
v0 — Baseline Reward
- Correct: +1.0; Wrong: −0.1
- None correct: +1.0; None wrong: −0.5
- Length penalty outside 30–768 token window
- Answer-driven only — no
<think>format checks
v1 — False Positive Penalty
After the model learned to say "None", it started saying it on answerableproblems too. Fix: when ground truth is not None and model outputs None, deduct−0.8 (the harshest single penalty).
v2 — Weird Token Penalty
GRPO training produced a peculiar artifact: the model learned to insert non-ASCII characters (private-use Unicode, fullwidth symbols) into answers — likely reward hacking to match ground truth strings.
Fix: A character-level whitelist allowing ASCII + Greek letters + math operators + arrows. Each out-of-whitelist character penalized −0.01.
Effect: Weird token rate dropped from 43.5% to 0%.
Core lesson: Length penalty, short-response penalty, false positive penalty, and weird token penalty are all necessary. None can be omitted.
Final Results
| Metric | Score |
|---|---|
| valid_1000 (Overall) | 55.2% |
| None Recognition | 69.2% |
| False Positive Rate | 4.3% |
| Weird Character Rate | 0% |
| High School Math | 66.8% |
| GSM8K Level | 67.8% |
| Level 3 | 57.4% |
| Level 4 | 42.6% |
| Olympiad | 15.9% |
Final pipeline: Base → SFT (None + Math) → GRPO (6ep, K=10) → GRPO Continue (higher temperature, 2ep). Improvement over baseline: +17pp.
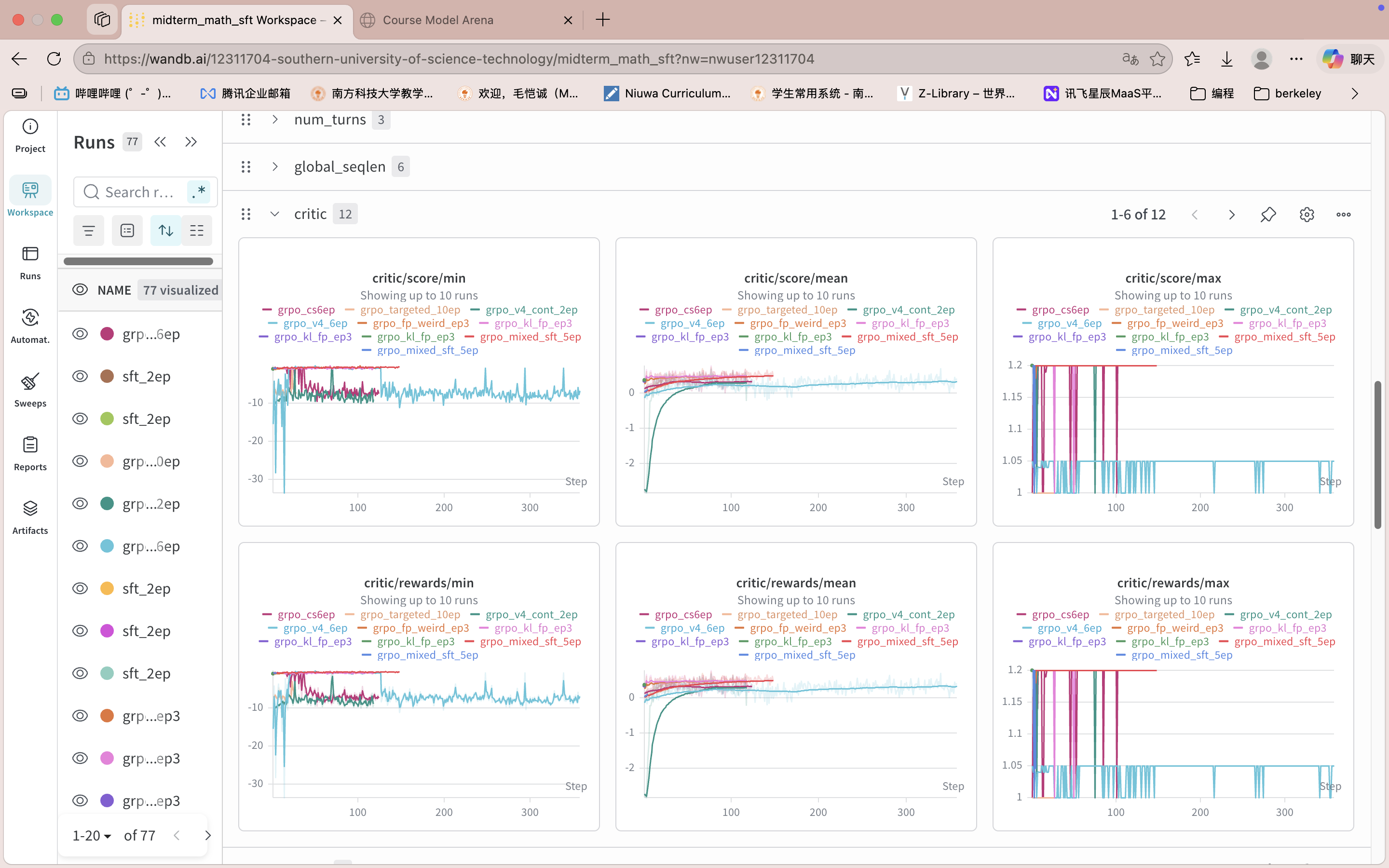

Key Takeaways
- SFT has limits: For small models, SFT alone cannot substantially improve reasoning. The pass@k signal is a better indicator of capability than greedy accuracy.
- RL prerequisite: RL requires that the model's sampling distribution already contains correct answers (pass@k >> greedy). If the model cannot sample correct solutions, RL has nothing to optimize toward.
- Reward design is the hardest part: Expect 3+ iterations. Every penalty you add can create a new reward hacking vector. Test each version against a diverse validation set.
- Order matters: Build math capability first (GRPO), then teach refusal (SFT), then consolidate both (GRPO). Reversing this order caused massive false positives.
- Team workflow: Clear communication with data teams is essential — explain not just what you need but why, with concrete examples.