GRPO 后训练数学推理:从 SFT 到 RL 的 Qwen3-0.6B 实验报告
基于 Qwen3-0.6B-Base,系统探索 SFT 到 GRPO 的后训练流程,通过奖励函数设计与 None 判别将数学推理准确率从 38.2% 提升至 55.2%。
基本信息
- 姓名: 毛恺诚
- 学号: 12311704
- 组号: Group 4
- 贡献: 负责后训练
个人贡献概览
本人作为 Group 4 后训练流程负责人,全程负责模型的 SFT 训练与 GRPO 强化学习训练实验。核心贡献包括:
- 跑通 SFT 与 GRPO 完整训练链路(从 Base 到最终提交的模型)
- 在 GRPO 中设计并迭代 3 版 Reward 函数,解决可能的 Reward Hacking、False Positive、怪字输出等关键问题
- 构建 None 判别训练数据,使模型学会识别不可解问题
- 完成 20 轮+实验,将模型准确率从 Baseline 38.2% 提升至 55.2%(+17.0pp)(均为本地测评正确率)
- 对训练好的模型进行本地评测,为数据组提供反馈
本人贡献与组内其他成员的区别: 我负责了全部的模型后训练与 Reward 设计流程,同时还兼任了检查模型输出、提供训练数据集构建思路的任务。
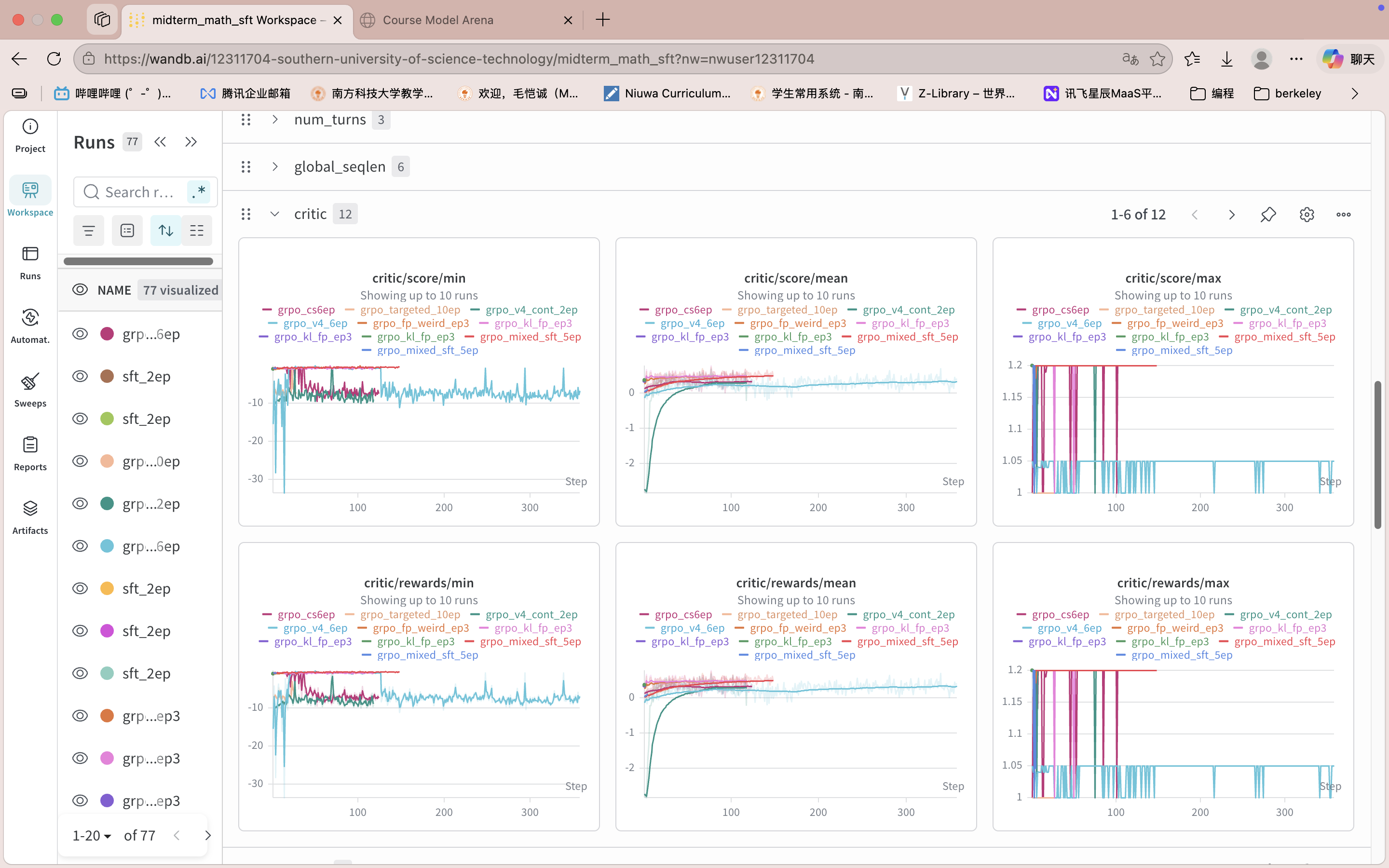
需要提前说明的: 由于磁盘空间大小限制,很多SFT或者RL实验的checkpoint及相应验证集输出在评测完即删除,无法提供截图support模型的正确率,只能提供WandB训练曲线截图来佐证实验过程。
第一阶段: SFT 流程跑通与瓶颈发现
冷启动 SFT
项目初期,我首先使用数据组产出的相对比较脏、质量比较低的冷启动数据集 coldstart_llm_A_think(8,323 条,含 <think> 推理链),对 Qwen3-0.6B-Base 进行全量 SFT 微调(后续还进行了同样数据集的LoRA微调,效果略强于Full Fine Tuning)。
训练配置:
- Epochs: 4
- Learning Rate: $2 \times 10^-5$
- 框架: 通过 DeepSpeed + openrlhf.cli.train_sft 实现, 用 train_sft.py 包装
结果: SFT 后模型达到 39.5%(valid_1000),略超 Baseline 38.2%,但提升有限。
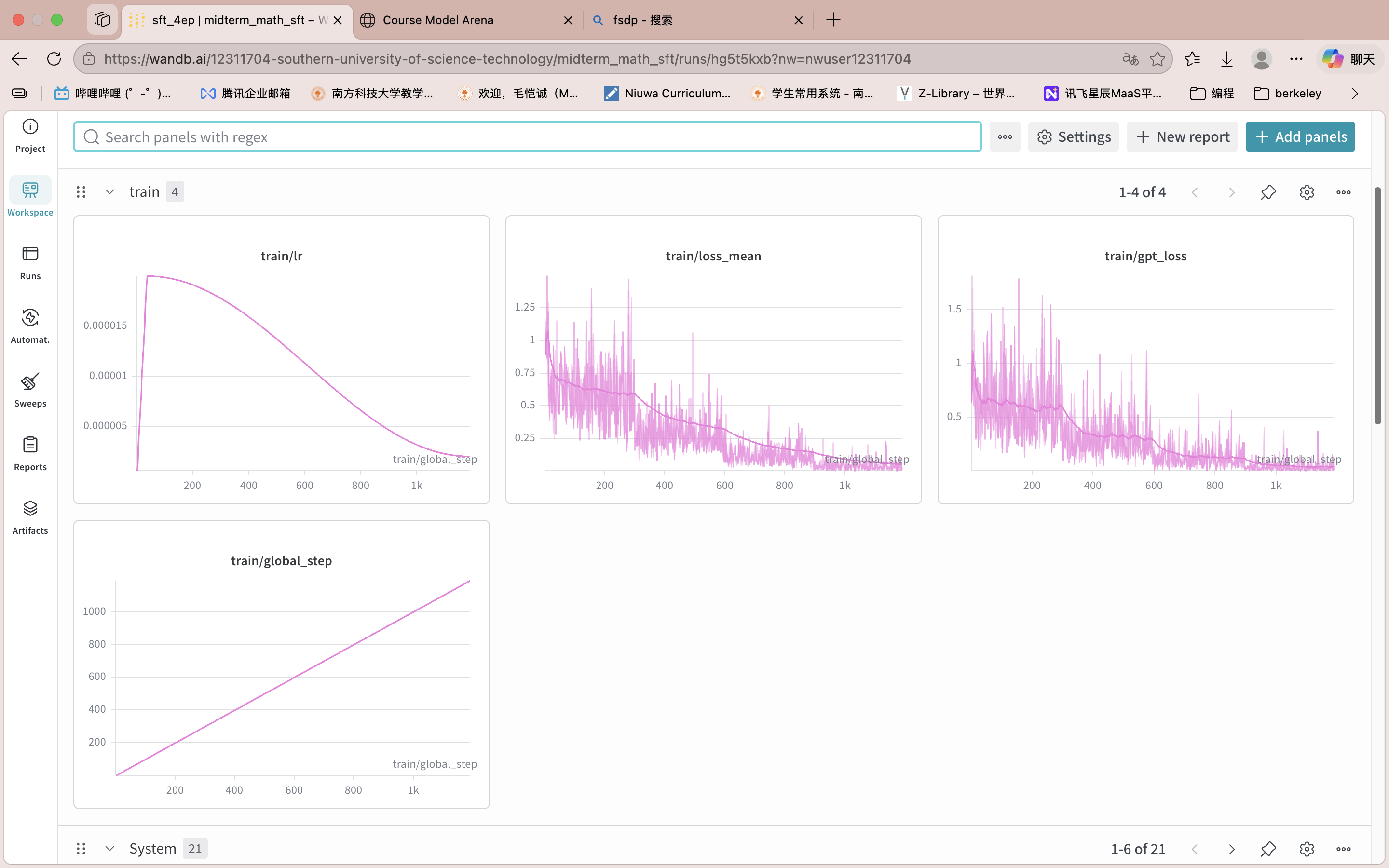
扩展数据后的退步
我尝试在 coldstart 8,323 条基础上,并入由小组数据组成员制作的高质量的新数据集 47_workshop、gjt_SFT_Data、seeker_SFT_Data,在此基础上进行 SFT 训练(改为 3 epochs,其他配置不变)。这次训练的目的是验证数据量增加是否能突破 SFT 的瓶颈。
结果: 准确率降至 36.7%,反而低于 Baseline。这一结果说明:
- 高质量但新来源的数据集破坏了原有数据分布,使得模型拟合了新数据的特征,导致性能下降。
- 即使有高质量的数据,可能SFT并不能直接带来模型能力的提升。
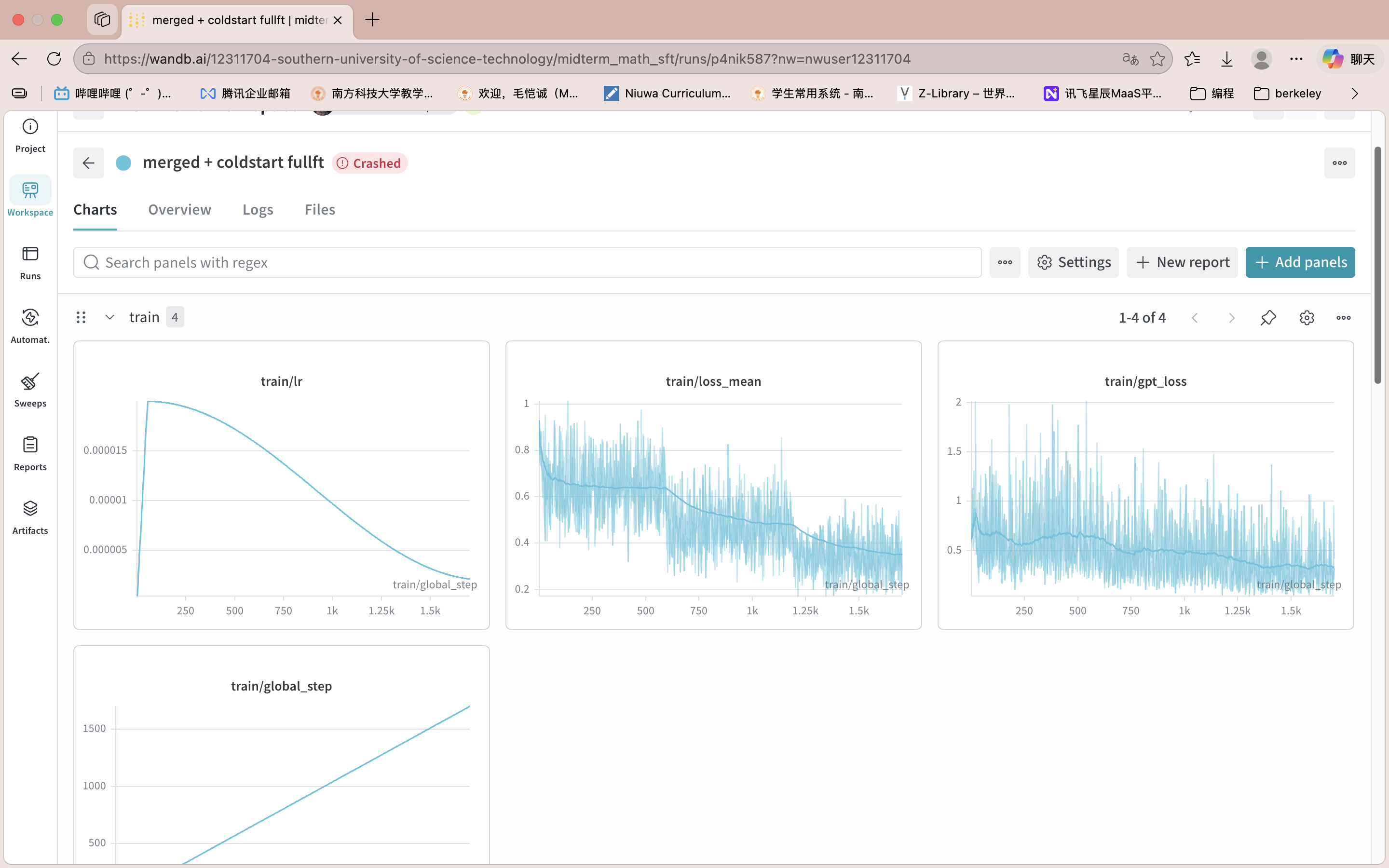
阶段结论
单纯依靠SFT和高质量数据没有办法带来直接的提升。但同时在一次微不足道的尝试中,我注意到一个关键信号:Base 模型的 pass@5 达到 62.6%,说明模型本身具有解题能力,只是 Greedy 解码时不稳定。这一点也与 Yue 等人关于 RLVR 能力边界的观察一致:当前 RLVR 更像是在挖掘 base model 已有采样分布中的潜力,而不一定创造全新的推理模式。这促使我转向强化学习方法——通过在线采样缩小 Greedy 与 Pass@k 之间的差距,使得模型的采样分布能够更加贴近validation数据集。
第二阶段: 转向 RL — GRPO 验证有效
为什么选择 GRPO
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 使用的核心算法。与 SFT 不同,GRPO 通过在线采样 $K$ 个答案、计算组内相对优势(Advantage),直接优化模型的生成分布,天然适合缩短 Greedy 与 Pass@k 的差距,而且不需要额外的标注数据。
数据准备
我从数据组新构建的高质量 SFT 数据中过滤出含 \boxed 的数学题(可提取 Ground Truth 答案),专门排除了general的问答题(所谓用来教会模型说话的题),构造 1,772 条 GRPO 训练 prompt(Parquet 格式),含 40 条 None 题。
训练与结果
GRPO 配置:
- 框架: verl 0.7.1
- $K=10$, Temperature $=0.7$, LR $=1 \times 10^-6$
- 单卡 RTX 5090 32GB(Actor 模型 + vLLM rollout 双引擎)
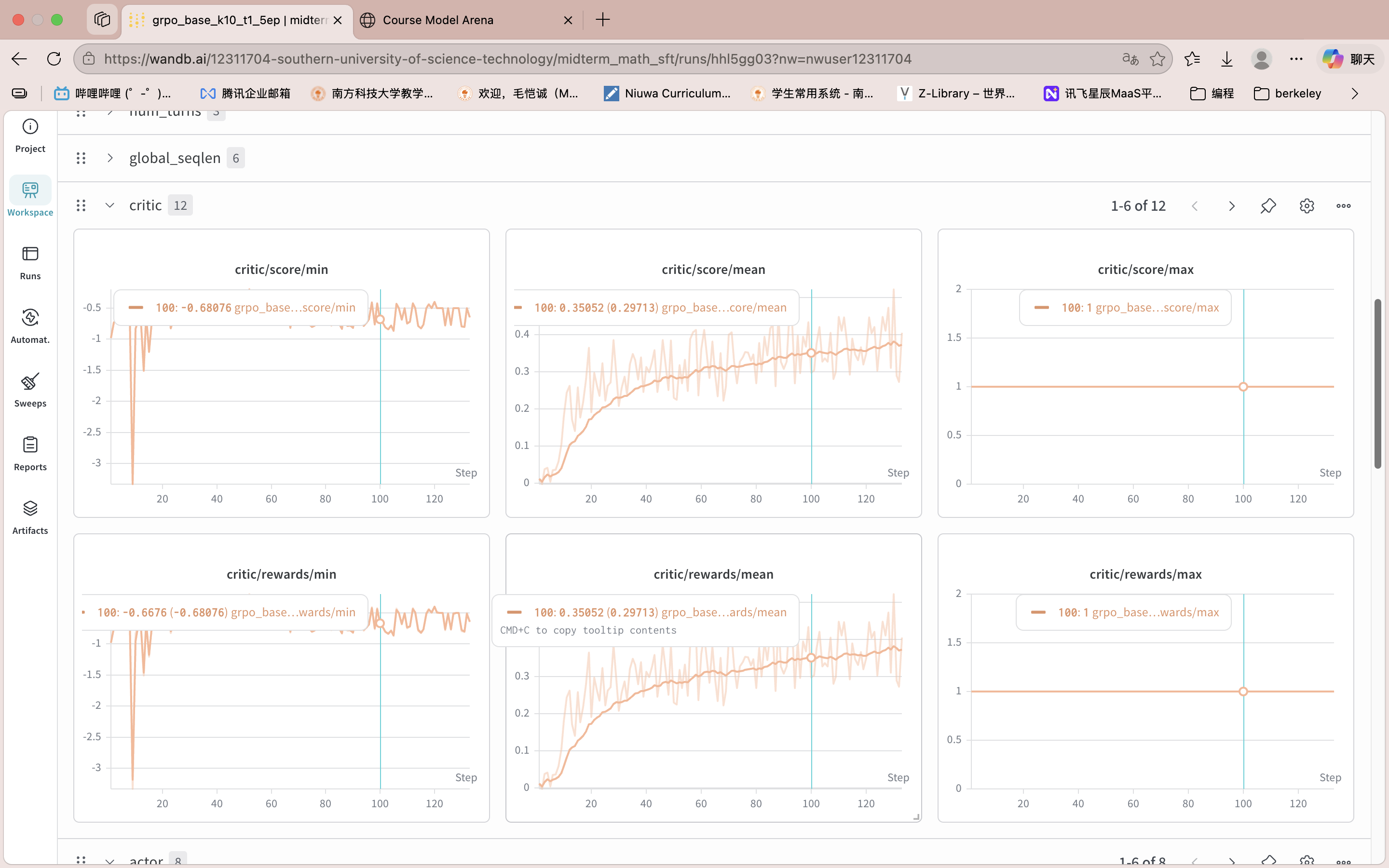
直接从 Base 模型启动 GRPO 训练(5 epochs),结果如下:
| 模型 | 训练方式 | 准确率 |
|---|---|---|
| Base (Qwen3-0.6B) | 无 | 36.2% |
| SFT Coldstart (最佳) | Full SFT | 39.5% |
| GRPO from Base | GRPO 5ep | 46.6% |
关键发现: GRPO 从 Base 直接训练拿到了 46.6%,比最佳 SFT 高出 7.1pp,比 Base 提升 10.4pp。首次验证了 RL 在数学推理任务上显著优于 SFT。
第三阶段: 加入 None 判别 — 最大提升
动机
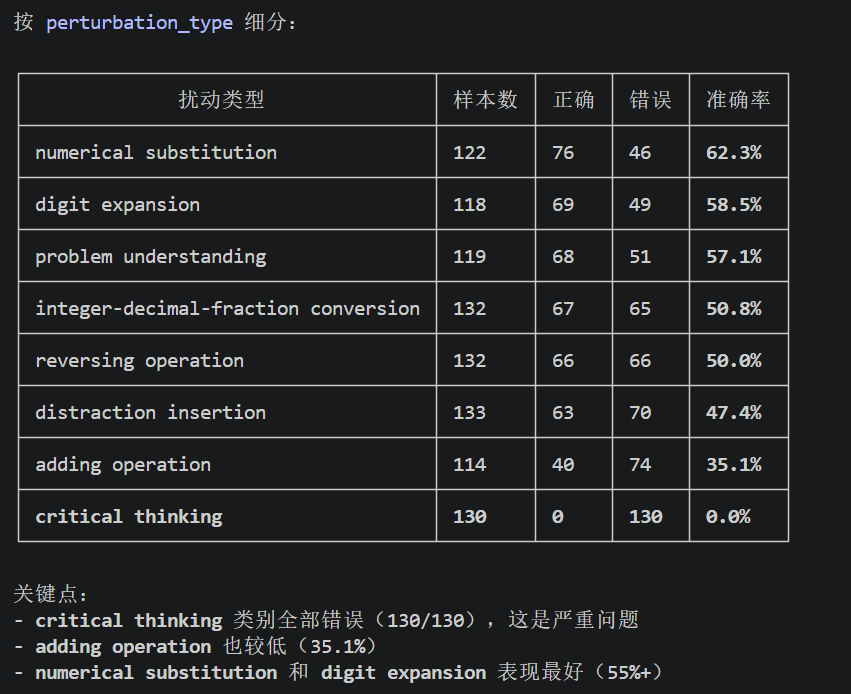
验证集中有 13% 的题目(Critical Thinking)故意缺少信息(如条件不足),正确答案应为 None。之前的模型——无论是 SFT 还是 GRPO——都几乎不会说"不知道",尤其是当前训出来的GRPO,模型在验证集per-type上这类题上得 0 分。
SFT 教 None → GRPO 巩固
鉴于模型经过了GRPO后仍然完全没有critical thinking题的能力,我设计了一个两阶段方案:
- SFT 阶段: 用 150 条含完整"条件检查 → 发现缺失 → None"推理链的 None 训练数据 + 400 条 coldstart,对前一个最好的GRPO checkpoint 做 SFT(lr $=2 \times 10^-6$, 2 epochs)
- GRPO 阶段: 将 SFT 后的模型继续 GRPO 训练,在 Reward 函数中给 None 正确的回答额外加分
实验结果
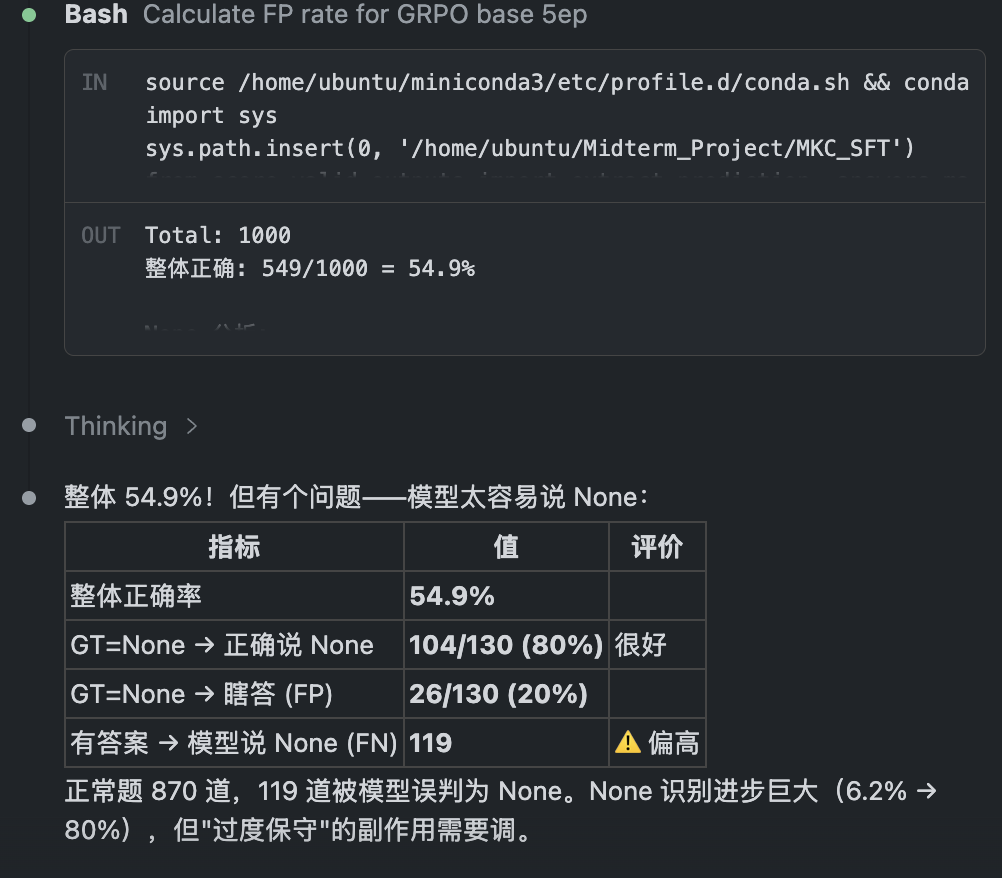
注:由于 None 题在验证集中占比不高,且模型之前完全不会说 None,所以 None 识别率的提升对 Overall 准确率的提升非常显著。加入 None 判别后,模型的 Overall 准确率从 46.6% 跃升至 55.7%,None 识别率从 0% 飙升到 80%,False Positive 率控制在 14%。(False Positive 指模型在有解题目上错误地说 None 的比例)
| 模型 | Overall | None | FP | Weird |
|---|---|---|---|---|
| GRPO Base→ep5 (无 None) | 46.6% | 0% | 3.8% | — |
| SFT None only | 40.7% | 67.7% | 22.1% | 10.8% |
| GRPO Mixed (SFT→GRPO) | 55.7% | 80.0% | 14.0% | 14.0% |
关键insights:
- 两阶段方案(GRPO→SFT→GRPO)效果最好,None 识别率从 0% 提升到 80%
- 必须先 GRPO 建数学能力,再 SFT 教 None。如果从 Base 直接做 None SFT,FP 爆炸到 45%+
- 在none问题上,答对的reward我设成1.2(比普通问题高0.2),但是我对False Positive的惩罚与正常回答错误的惩罚一样低,导致FP率极高
- 注意到在这些模型上,都出现了怪字(weird token)现象,并且几乎每一题都会有,位置基本在回答最末尾,所以后续还需要在reward中加入怪字惩罚
确定优化路线
至此,我明确了后续所有实验的核心路线:
Base → SFT (None+Math) → GRPO (6ep, K=10) → GRPO continue (调高Temperature再训练2ep)
这一路线在后续实验中大致被验证为最优。
第四阶段: 精细化优化 — Reward 函数迭代
Reward 函数是 GRPO 训练最核心的组件,决定了模型优化的方向。我经历了 3 个主要版本的设计迭代,逐步收敛到稳定方案。
v0 —— 初始设计:区间长度惩罚 + 纯答案驱动
第一版 Reward 如下:
- 正确答案: +1.0;错误: −0.1
- None 正确: +1.0;None 错误: −0.5
- 长度区间惩罚:30–768 tokens 零惩罚;<30 tokens 扣 0.3(防空回复);>768 tokens 渐增惩罚
- 不检查 Think 格式,纯答案驱动,减少 Reward 信号噪声
v1 —— 加 FP 惩罚:不能让模型无脑输出None
模型学会了 None 判别后出现副作用:在有解题目上也说 None(False Positive),大大拉低了 Overall 准确率。
修复: 对于 Ground Truth 不是 None 的题目,模型输出 None → 扣 0.8(最严厉的单条惩罚)。
v2 —— 加怪字惩罚(Unicode 噪声清除)
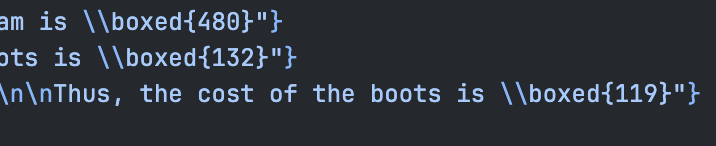
GRPO 训练中出现了独特现象:模型学会在答案中插入大量非 ASCII 乱码(如私用区字符、全角符号),推测是为了"碰巧"匹配 Ground Truth 而 Reward Hacking。
我设计了一个精密的白名单机制:允许 ASCII + 希腊字母 + 数学运算符 + 箭头 + 上下标等 Unicode 范围,每个不在白名单内的字符扣 0.01。
效果: 怪字率从 43.5% 降至 0%。
 惩罚前:GRPO Mixed 训练出现怪字现象
惩罚前:GRPO Mixed 训练出现怪字现象
 惩罚后:输出结果正常
惩罚后:输出结果正常
经过 3 个版本的迭代,Reward 函数最终收敛。核心教训:Reward 设计是 RL 最核心的难点,长回复惩罚、短回复惩罚、FP 惩罚、怪字惩罚四者缺一不可。
最终成果
必须要说明的是,虽然在前期探索中,我发现SFT虽然降低了模型的Overall准确率,但是我在最后用最好的数据SFT并且测试它的pass@k的时候,我发现它的表现非常好,具备RL训练的潜力,所以最后还是以SFT→GRPO→GRPO的方式进行最终模型的训练。

除此之外,在V4 cont之后我还另外使用了补充数据进行了一轮针对性训练,但是效果并没有想像中好,过度追求某一类题型的正确率会降低模型总体的采样效率并且导致过拟合,因此最终还是使用了V4 cont作为最终提交的模型。
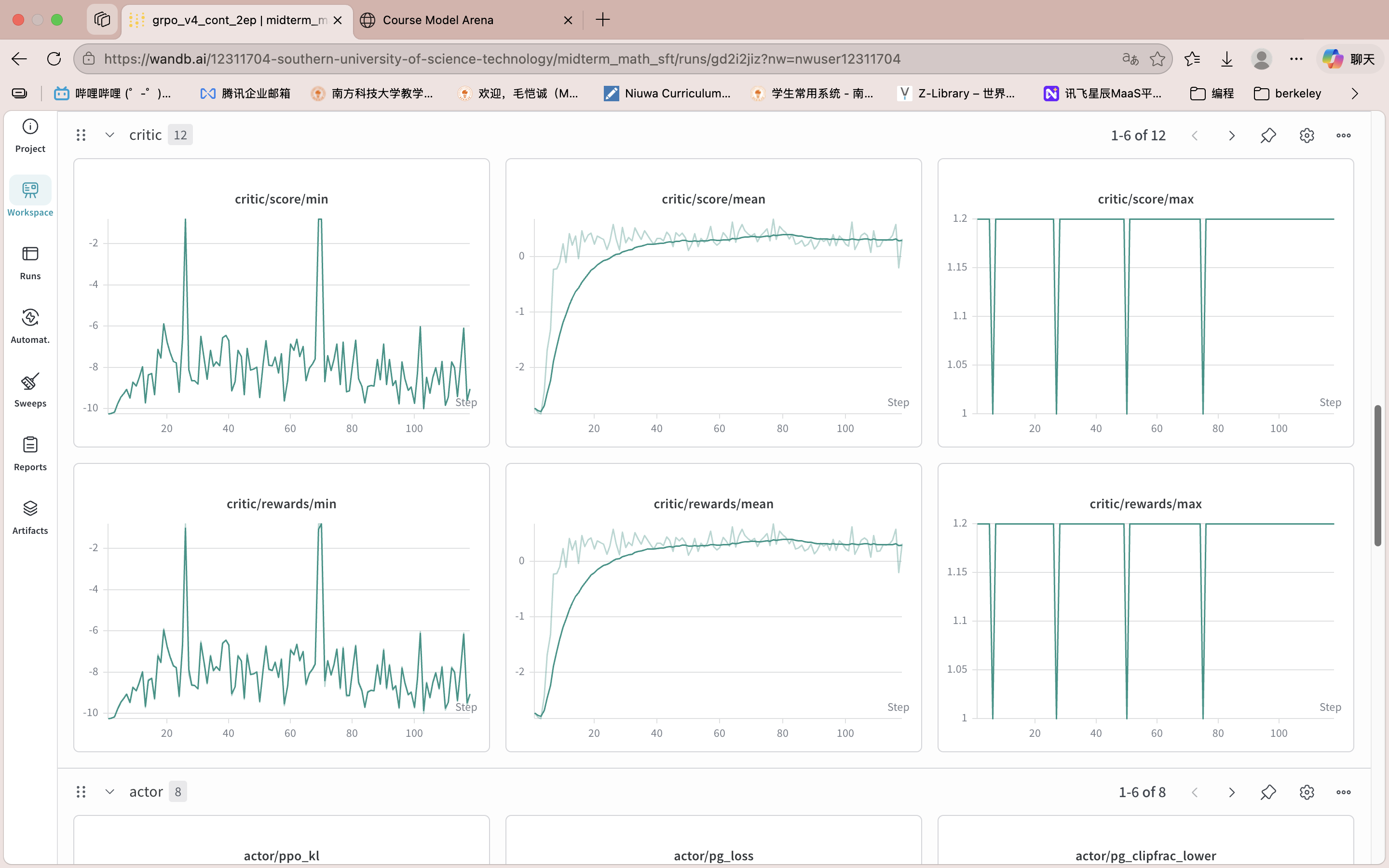
全部实验结果总览
经过 14 轮系统实验,我完成了从 SFT 到 GRPO 的完整探索:
| # | 模型 | 训练方式 | Overall |
|---|---|---|---|
| 1 | Base | 无 | 36.2% |
| 2 | SFT Coldstart | SFT 3ep | 39.5% |
| 3 | SFT Merged | SFT 3ep | 36.7% |
| 4 | GRPO Base→ep5 | GRPO 5ep | 46.6% |
| 5 | SFT None only | GRPO→SFT | 40.7% |
| 6 | GRPO None→ep5 | SFT→GRPO | 54.9% |
| 7 | GRPO Mixed→ep4 | SFT→GRPO | 55.7% |
| 8 | SFT Mixed | GRPO→SFT | 45.0% |
| 9 | GRPO Mixed cont | SFT→GRPO + FP 惩罚 | 55.4% |
| 10 | SFT Base V4 | Base→SFT | 28.5% |
| 11 | V4 ep6 | SFT→GRPO 6ep | 53.5% |
| 12 | V4 cont (final selected) | SFT→GRPO→GRPO cont | 55.2% |
| 13 | GRPO Targeted | Final→GRPO targeted | 55.7% |
| 14 | SFT Targeted | Final→SFT targeted | 50.2% |
最终交付模型
路径: /data/experiments/grpo_v4_cont/merged_final
| 评测指标 | 得分 |
|---|---|
| valid_1000 (Overall) | 55.2% |
| None 识别率 | 69.2% |
| False Positive 率 | 4.3% |
| Weird Character 率 | 0% |
| valid_math (高中) | 66.8% |
| valid_gsm8k (小学) | 67.8% |
| valid_math_level3 | 57.4% |
| valid_math_level4 | 42.6% |
| Olympiad | 15.9% |
对比 Baseline: 38.2% → 56.1%,提升 +17.9 个百分点。

个人反思
技术反思
- SFT 的局限性: SFT 能让模型去拟合训练数据的分布,对于Qwen3-0.6B这样参数量非常小的模型来说,单纯的 SFT 很难带来实质性的能力提升,甚至可能因为数据分布的改变而导致性能下降。在实验的最初期,我还没意识到这一点,所以一直提升不了正确率,确实是非常upset的。所以这个经验告诉我,SFT之后直接greedy解码出来的结果没有那么好,并不一定是训练没做好,而是需要转向RL来提高模型的采样效率。
- RL的直觉: 做RL的先决条件是模型的采样分布中已经包含正确答案(即 Pass@k 已经远高于 Greedy)。如果模型连正确答案都采样不出来,RL 就无从优化。这个经验判断与 RLVR 相关研究中"base model 的大 $k$ pass@k 可以视为当前 RL 可利用能力上界"的结论一致。而GRPO的核心则在于设计一个合理的Reward函数(这个必须要通过试错才能找到),来提高模型的采样效率。
项目管理反思
- 数据质量的重要性: 训练数据的质量不仅包括其正确性,还有其类型的分布是否均衡,是否包含模型需要学习的能力点(如 None 判别)。
- 如何使得团队成员的效率更高:下达指令时,不能假定他们理解自己的观点,因为实验是我一个人做的。必须给出我的观点的依据,解释清楚,告诉他们接下来要做什么、具体的步骤(最好是few-shot),这一点我觉得跟提高模型表现很相似。
参考文献
- Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? arXiv preprint arXiv:2504.13837, 2025.